A Unified Contrastive Representation Learner for Cross-modal Federated Learning Systems.
 A Unified TinyML System for Multi-modal Edge Intelligence and Real-time Visual Perception
A Unified TinyML System for Multi-modal Edge Intelligence and Real-time Visual PerceptionResearch Opportunity 3: A Unified Contrastive Representation Learner for Cross-modal Federated Learning Systems
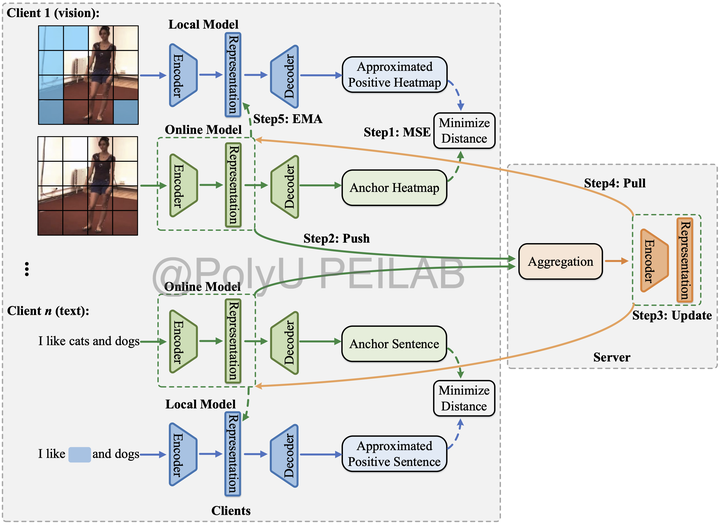
Illustration: Contrastive representation learners have achieved great advantages for modern visual tasks. Existing methods (e.g., CLIP, visialGPT, VideoCLIP, and UniFormer) are resource-expensive, thus are not suitable for the realistic scenarios of deploying federated learning applications. Meanwhile, the single data modality of conventional FL systems significantly limits the scalability and applicability. Building an economical and efficient representation learner is the key issue to implement downstream tasks. This requires us to design a new cross-modal federated learning framework, which tackles the multimodality fusion of latent features and provides higher performance over the single-modal paradigms.